See my Google Scholar for the most up to date list of academic publications.
My PhD Defense slides are here.
LABBench 2 — An Improved Benchmark for AI Systems Performing Biology Research.

Jon M Laurent, Albert Bou, Michael Pieler, Conor Igoe, Alex Andonian, Siddharth Narayanan, James Braza, Alexandros Sanchez Vassopoulos, Jacob L Steenwyk, Blake Lash, Andrew D White, Samuel G Rodriques
We introduce LABBench2, a benchmark for measuring real-world capabilities of AI systems performing scientific research tasks. While existing evaluations focus on knowledge and reasoning, meaningful progress requires measuring the ability to perform actual scientific work. LABBench2 comprises nearly 1,900 tasks that evaluate AI systems in realistic research contexts. We show that frontier models have improved substantially, yet LABBench2 presents a significant difficulty jump over prior benchmarks, with accuracy dropping 26-46% across subtasks, underscoring continued room for advancement in AI-driven scientific discovery.
Under review. Featured as an evaluation benchmark in OpenAI's GPT-Rosalind launch (May 2026), Anthropic's Opus 4.8 System Card (May 2026) and Fable 5 + Mythos 5 System Card (June 2026).
Efficient Bayesian Experiment Design with Equivariant Networks
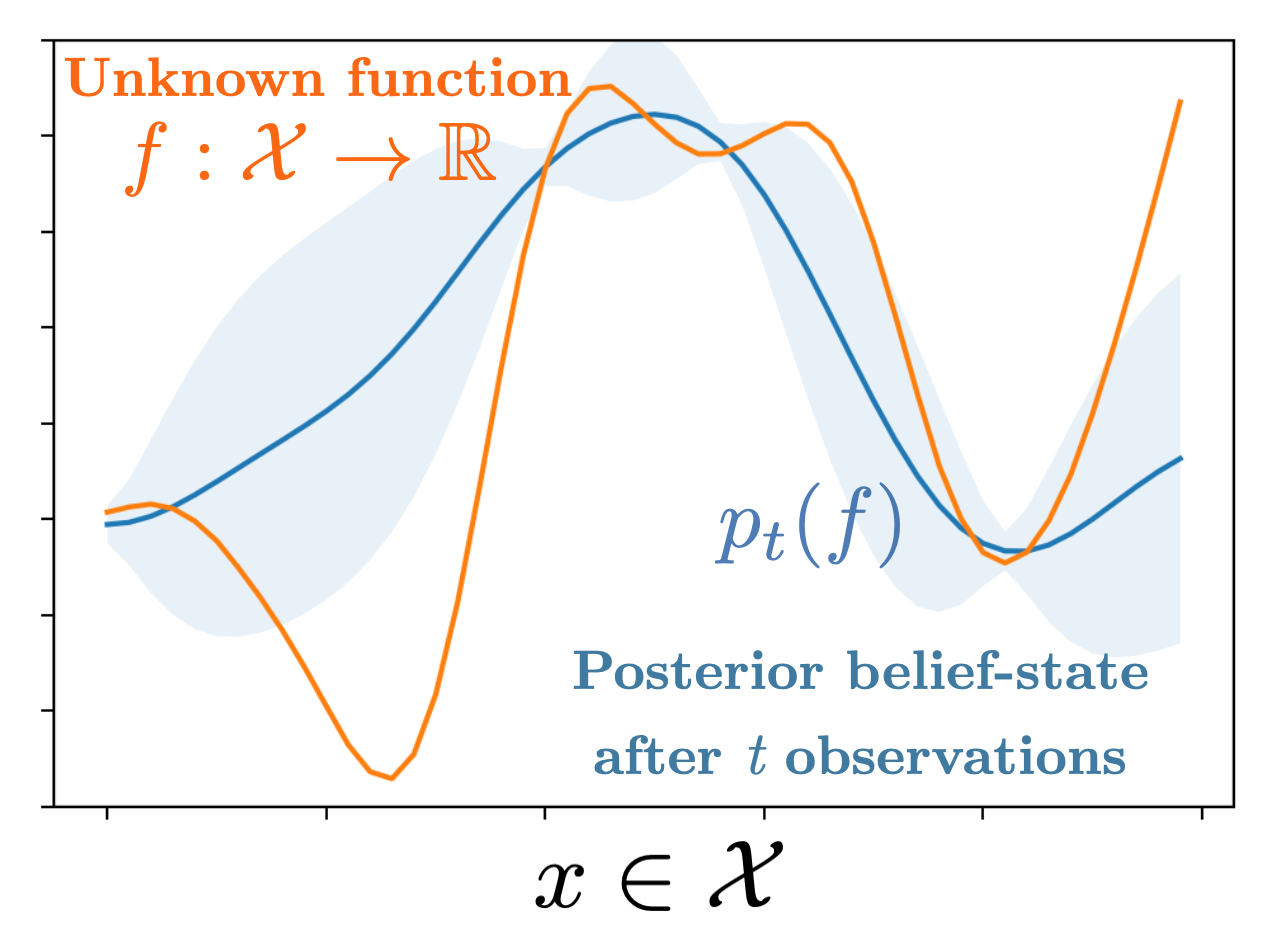
Conor Igoe, Tejus Gupta, Jeff Schneider
We study the challenge of belief explosion in Deep Learning approaches to Bayesian Experiment Design (BED), where the number of possible posterior beliefs grows rapidly as experiments progress. We show that selecting inductive biases for BED agents is crucial to addressing this problem and has been largely overlooked in prior work. We propose Graph Neural Network architectures that exploit domain permutation equivariance, achieving orders-of-magnitude improvements in sample efficiency over standard network parameterizations.
NeurIPS 2025.
Weighted Tallying Bandits: Overcoming Intractability via Repeated Exposure Optimality
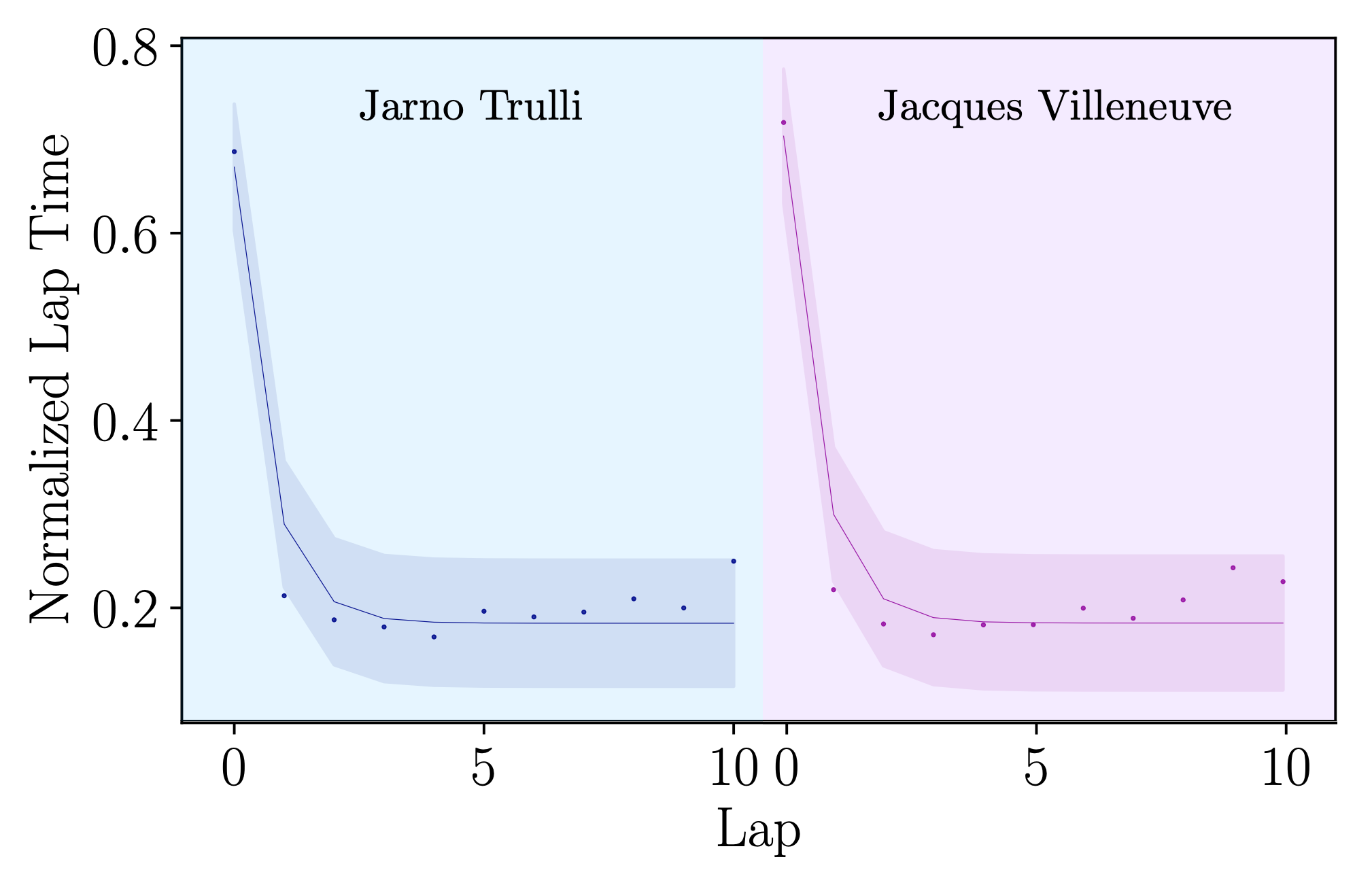
Dhruv Malik, Conor Igoe, Yuanzhi Li, Aarti Singh
We introduce the Weighted Tallying Bandit (WTB) problem setting, which generalizes previous online learning settings to capture the decay of human memory with time. We motivate the Repeated Exposure Optimality (REO) property and study the minimisation of Complete Policy Regret in WTB instances satisfying REO. We provide theory and simulation results showing how the Successive Elimination algorithm is well-suited for this class of problems.
ICML 2023.
Multi-Alpha Soft Actor-Critic: Overcoming Stochastic Biases in Maximum Entropy Reinforcement Learning

Conor Igoe, Swapnil Pande, Siddarth Venkatraman, Jeff Schneider
Robotic control requires intelligent decision-making in complex scenarios. Soft Actor-Critic is a popular DRL algorithm but its entropy-based learning objective introduces bias. We show how naively reducing the bias leads to slow or unstable learning. We propose Multi-Alpha Soft Actor-Critic which treats the entropy coefficient as a random variable, overcoming the bias and maintaining stability and efficiency in robotic control tasks.
ICRA 2023.
How Useful are Gradients for OOD Detection Really?
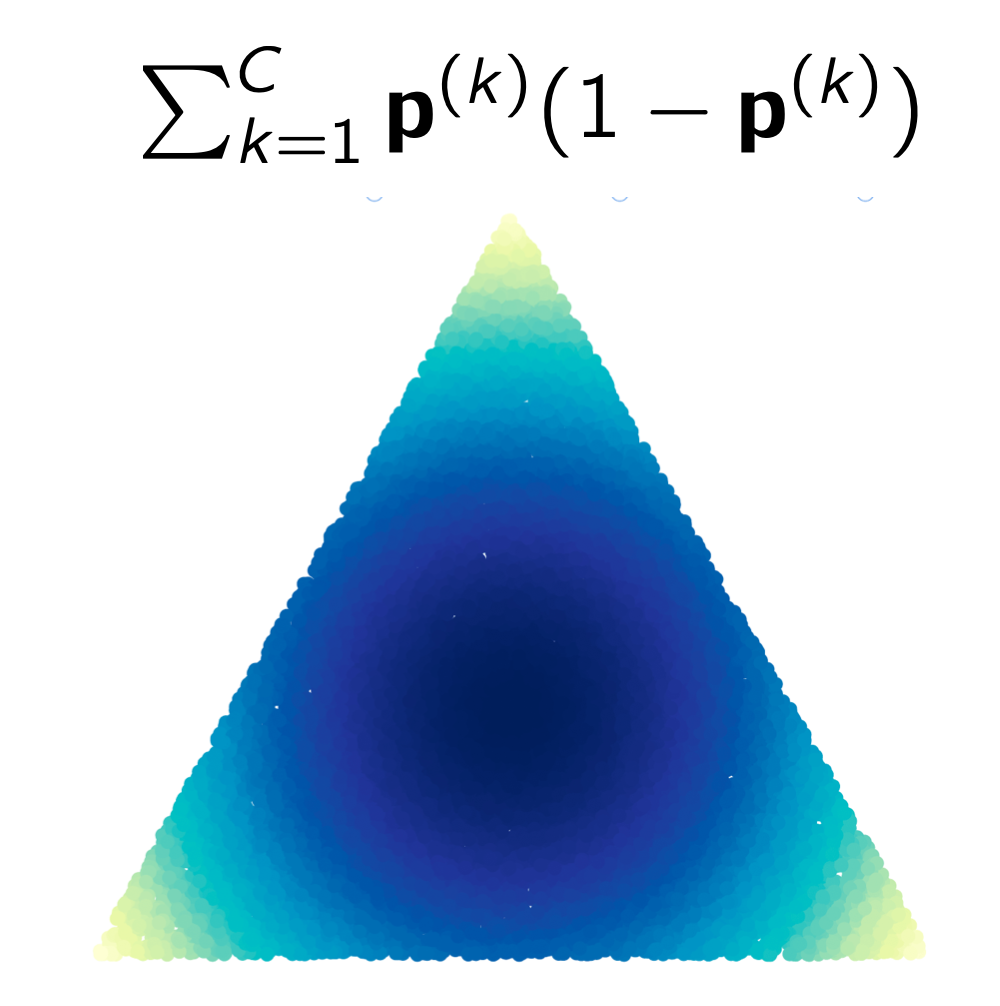
Conor Igoe, Youngseog Chung, Ian Char, Jeff Schneider
Detecting when a model is unable to make accurate predictions is crucial for real-world applications. Previous methods utilizing test-time gradients for OOD detection have shown competitive performance, but there are misconceptions about the necessity of gradients. In this work, we provide an in-depth analysis of test-time gradients and propose a general, non-gradient-based method of OOD detection.
arXiv 2022.
Multi-Agent Active Search: A Reinforcement Learning Approach
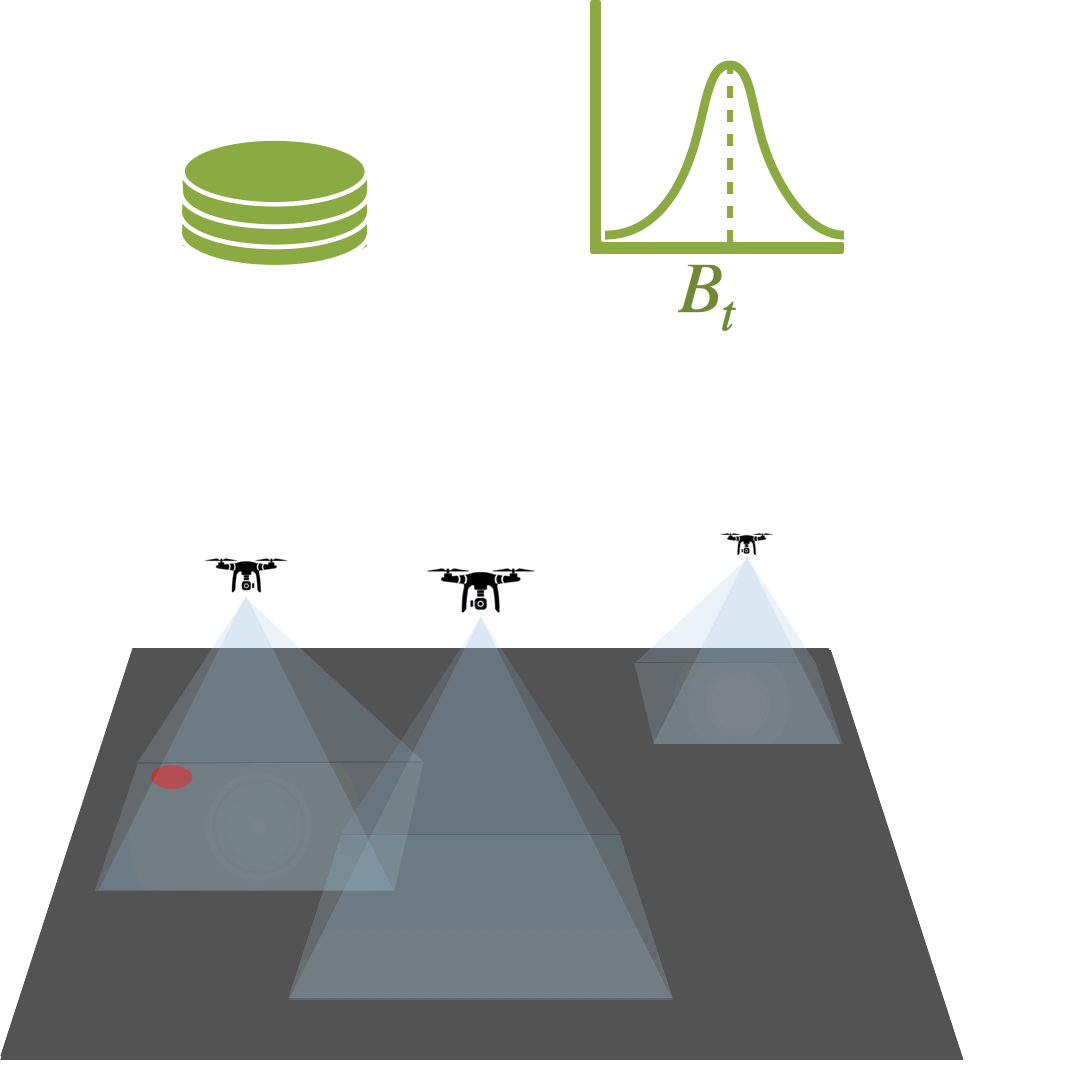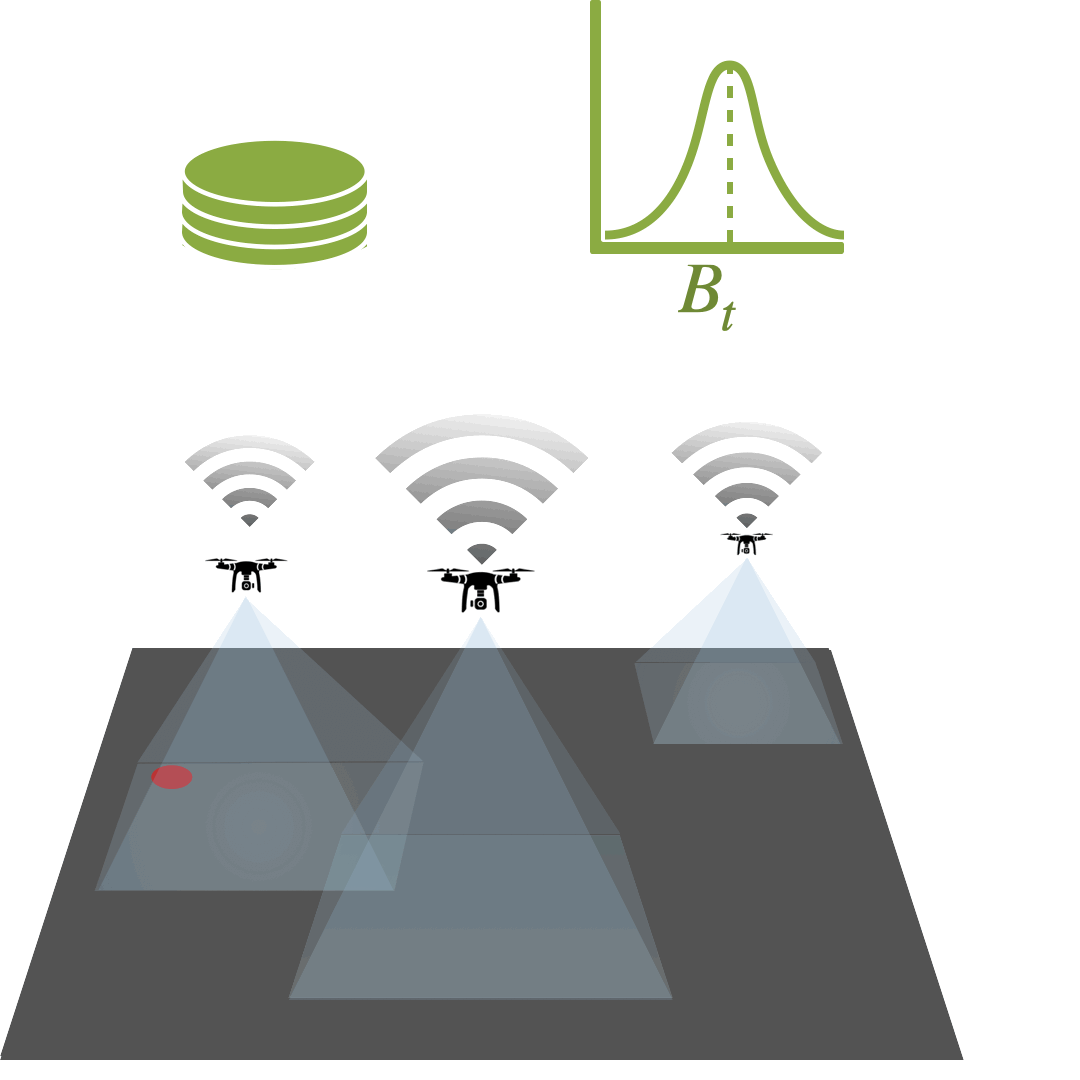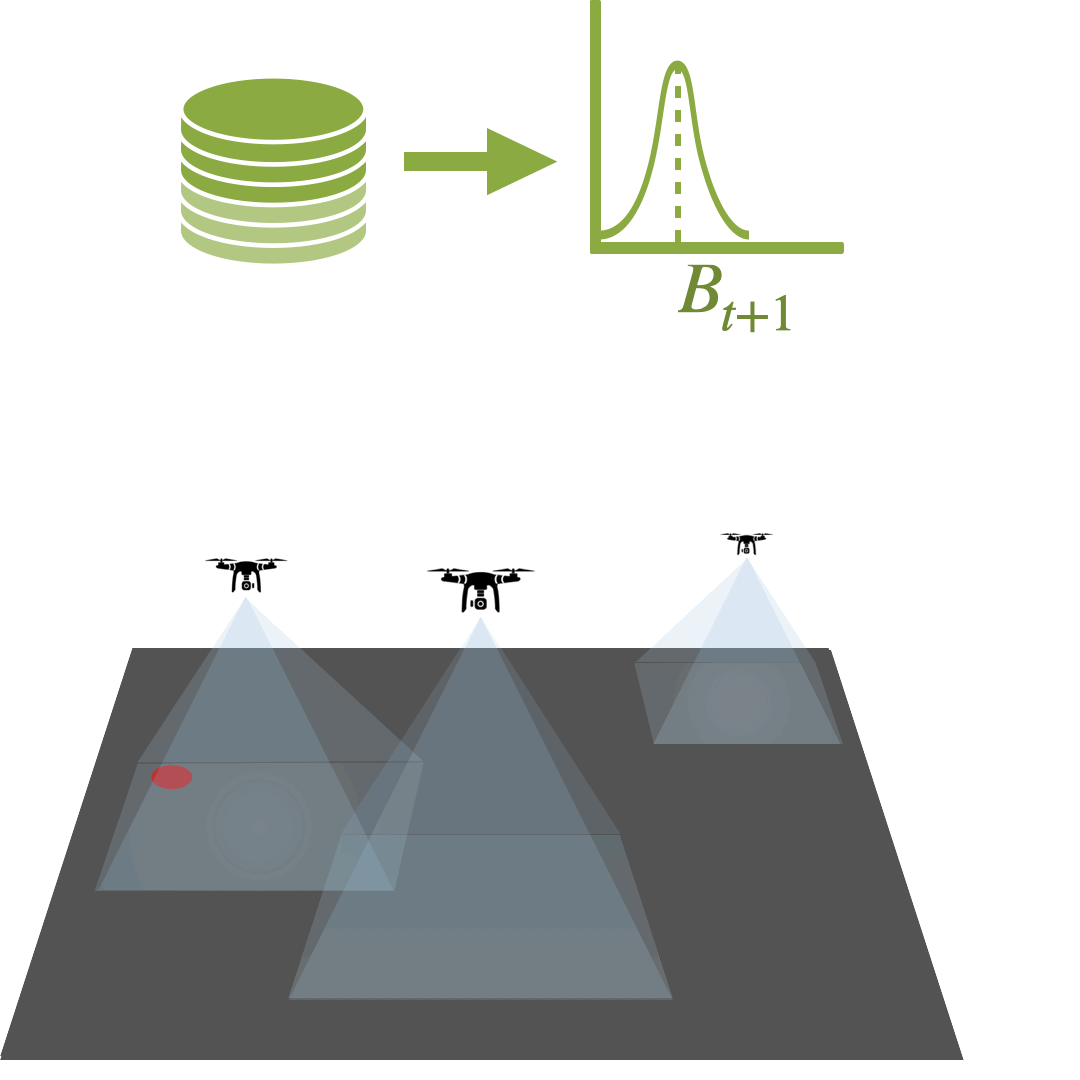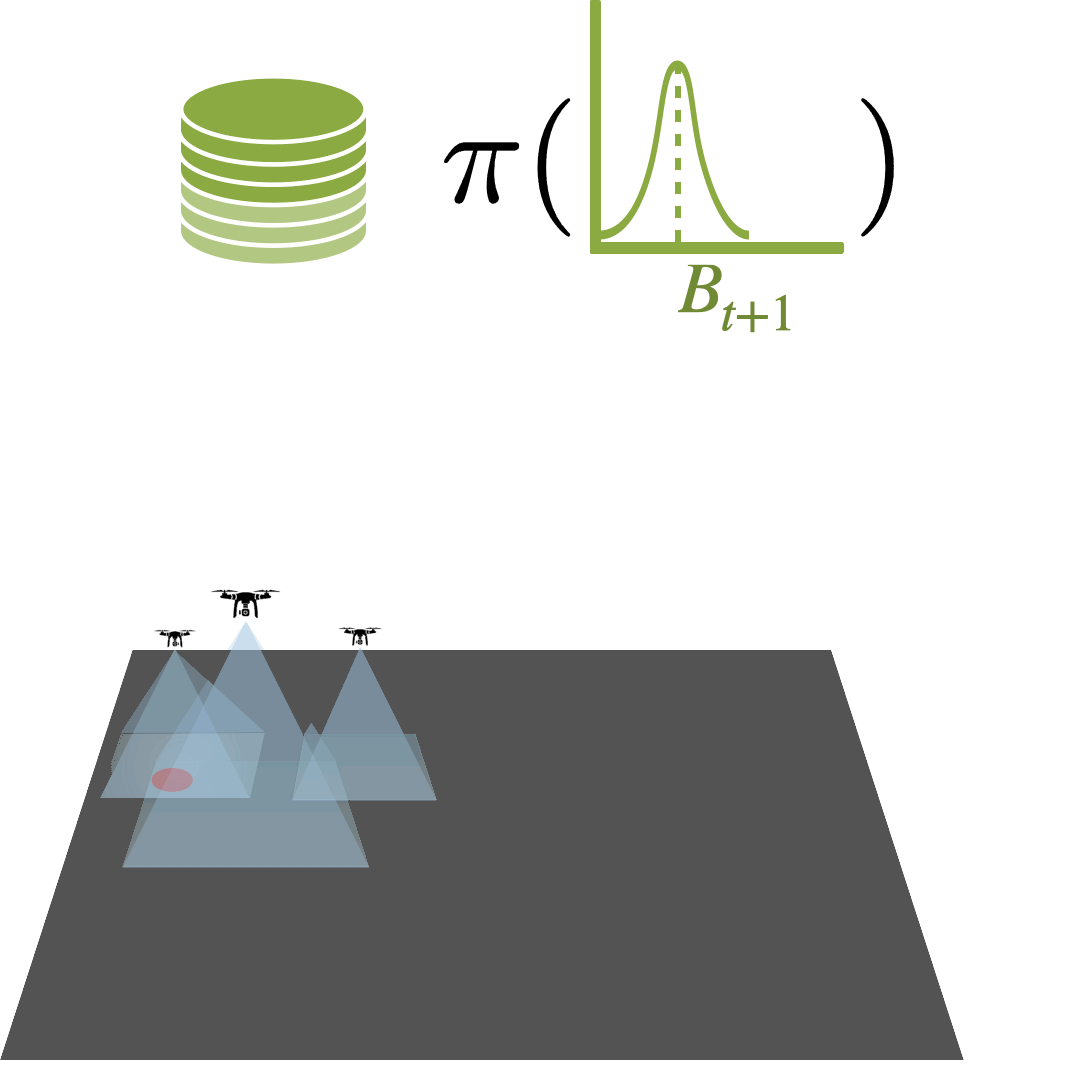
Conor Igoe, Ramina Ghods, Jeff Schneider
Multi-Agent Active Search (MAAS) is an active learning problem with the objective of locating sparse targets in an unknown environment by actively making data-collection decisions. We argue that Deep RL is a particularly strong choice for active search tasks from decision-theoretic and computational perspectives.
ICRA 2022.
Hierarchical Bayesian Framework For Bus Dwell Time Prediction
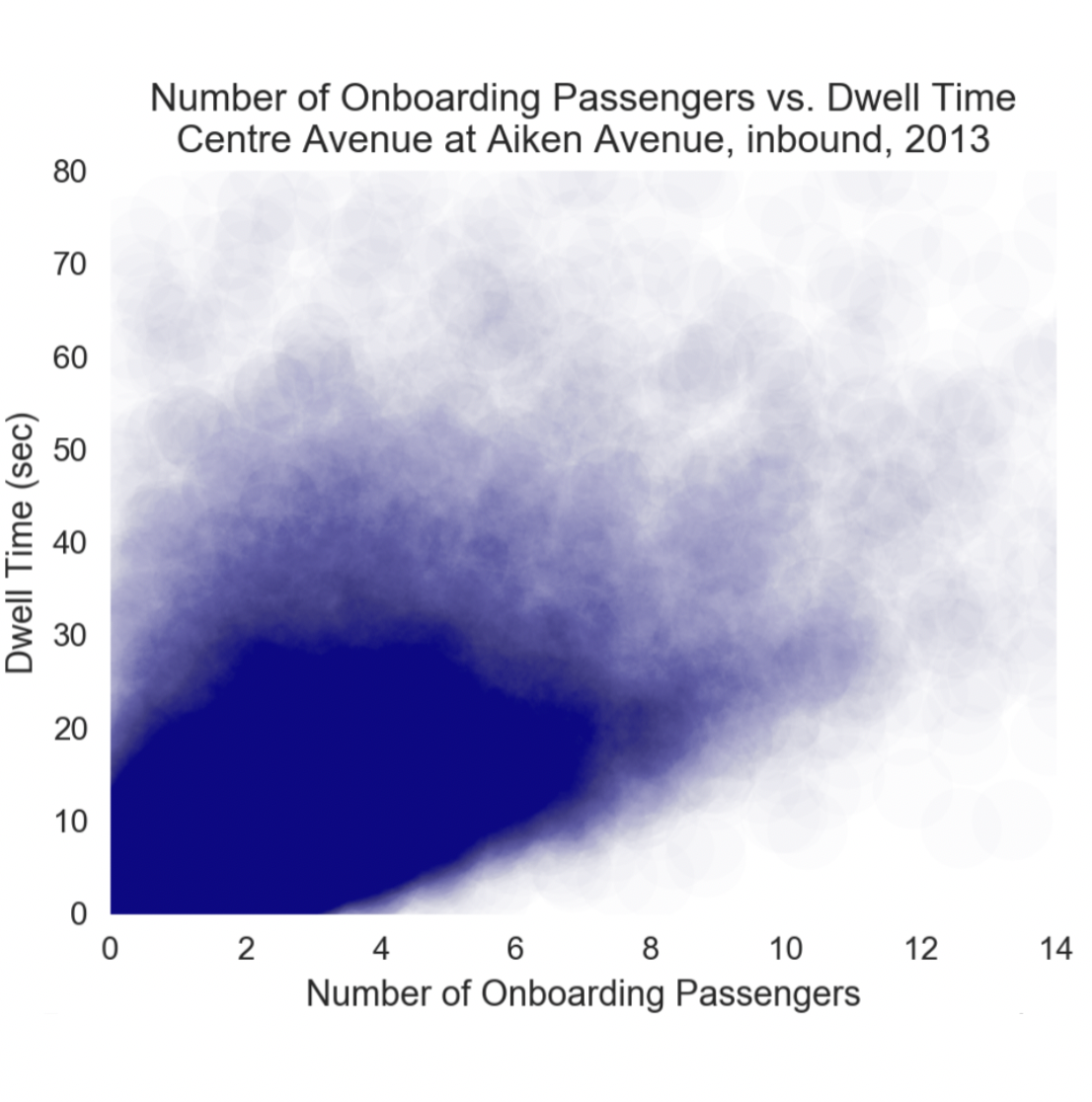
Isaac K. Isukapati, Conor Igoe, Eli Bronstein, Viraj Parimi, Stephen F. Smith
We develop Bayesian models for predicting bus arrival times at signalized intersections. Our approach accounts for uncertainty in bus dwell time, which is crucial for accurate predictions. We use minimal data and provide a rich description of confidence for decision-making. Our results show that our approach yields significantly more accurate predictions than standard regression and deep learning techniques, making it useful for real-time traffic signal optimization.
IEEE ITS 2020.
Multi-armed bandits with delayed and aggregated rewards
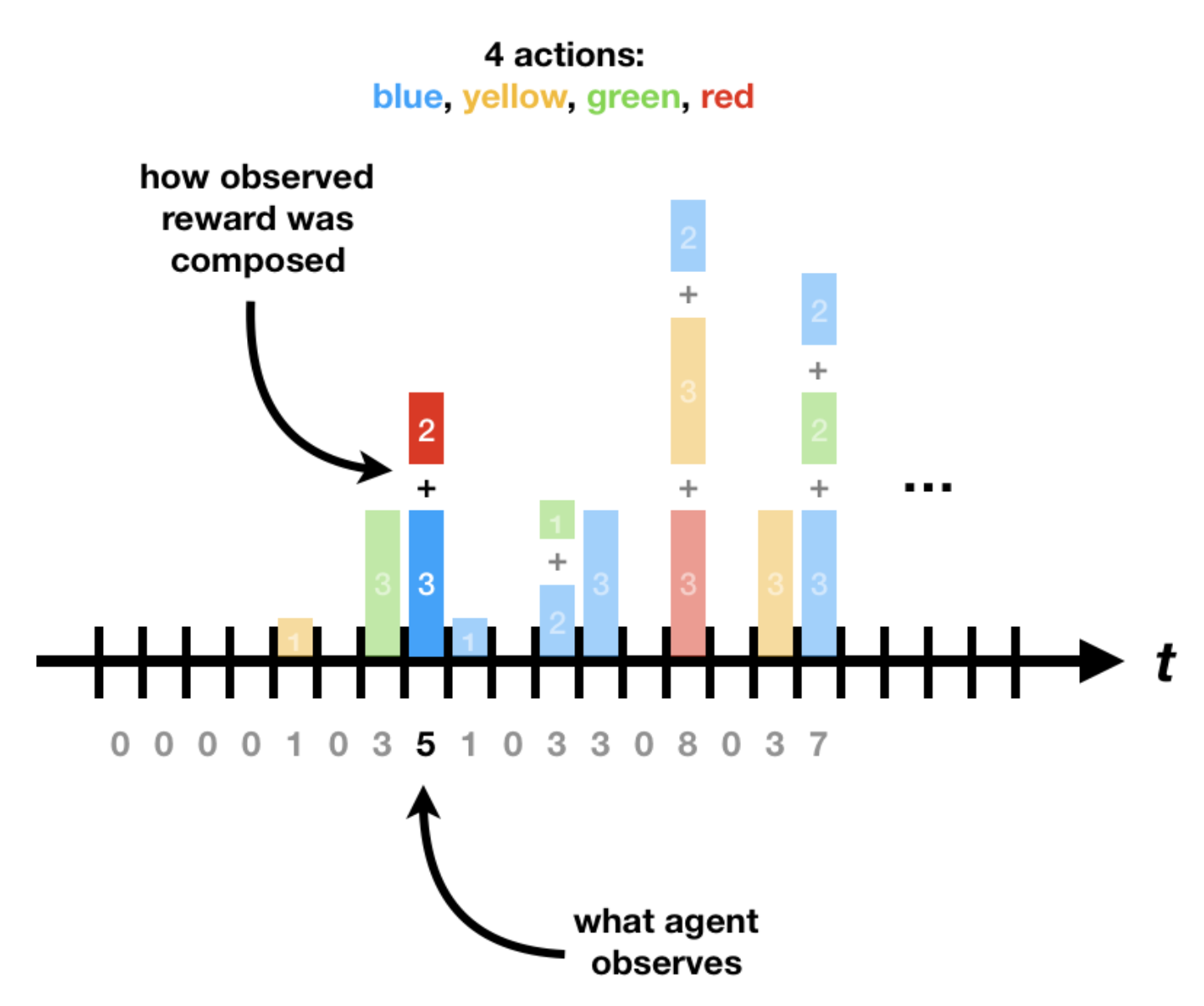
Jacob Tyo, Ojash Neopane, Jonathon Byrd, Chirag Gupta, Conor Igoe
We study the multi-armed bandit problem under delayed feedback. Recent algorithms have desirable regret bounds in the delayed-feedback setting but require strict prior knowledge of expected delays. We study the regret of such delay-resilient algorithms under milder assumptions. We empirically investigate known theoretical performance bounds and attempt to improve on a recently proposed algorithm by making looser assumptions on prior delay knowledge.
CCDC ARL 2019.